分子动力学计算常用于精细分析材料的性质,往往采用周期边界条件。对于多尺度计算和其他一些力学研究,周期边界条件不适用,需要设计人工边界条件[1 ] 。本文将针对一维线性原子链,运用机器学习设计人工边界条件。该方法需要的先验知识很少,且可以快速产生一系列边界条件。
传统的获得人工边界条件的方法有时间历史积分[2 ] 与在给定波数附近进行泰勒展开的方法[3 ] 等。本文提出的方法主要是受后者的启发。
1 原子链的人工边界条件
考虑一维无穷长原子链,每个原子与其邻近原子线性相互作用。归一化控制方程为
(1) $\begin{align} \ddot{u}_{j}=u_{j-1}+2u_{j}+u_{j+1} \end{align}$
(2) $\begin{align} \mathrm{e}^{{\rm i}(\omega t + j\xi )} \end{align}$
(3) $\begin{align} & \omega =2| {\sin}({\xi }/{2}) |, \xi \in \left[ -\pi ,\pi \right] \end{align}$
为色散关系。$\xi \in [-\pi ,0]$为右行波,$\xi \in [0,\pi ]$为左行波。
如果数值截断模拟有限长度内的原子链,需要在数值边界上设计人工边界条件。以左边界$u_{0}$为例,我们设计以下形式的线性边界条件
(4) $\begin{align} \sum\limits_{j=0}^N c_{j} \dot{u}_{j}+\sum\limits_{j=0}^N b_{j} u_{j}=0 \end{align}$
$N$表示边界条件用到的原子数,我们取$N=6$, $c_{0}=1$。其中$c_{j}$及$b_{j}$ ($j=0,1,\cdots,6$) 即为待定的边界条件系数。
(5) $\begin{align} {\begin{array}{l} \varDelta \left( \xi \right)=\mathrm{i}\omega \left( \xi \right)\sum\limits_{j=0}^N c_{j} e^{{\rm i}j\xi }+\sum\limits_{j=0}^N b_{j} e^{{\rm i}j\xi } \end{array}} \end{align}$
可以发现如果波数为$\xi $的左行波能够完全满足边界条件,则$\varDelta \left( \xi \right)=0$。而如果不能完全满足边界条件,$\varDelta \left( \xi \right) \ne 0$,就会产生反射。可以知道反射系数$R(\xi )=- {\varDelta (\xi )}/{\varDelta (-\xi )}$。
2 前馈神经网络
前馈神经网络是神经网络的一种,由一个输入层、若干个隐藏层和一个输出层组成。每一层由一组权重和一个激活函数组成,上一层的输出经过权重的线性组合和激活函数的映射之后输出给下一层隐藏层,直到最终输出。
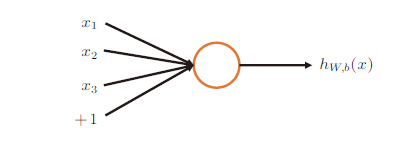
最简单的前馈神经网络结构如图1 所示(这是没有隐藏层的情况):
图1
(6) $\begin{align} {x}=\left( x_{1},x_{2},\cdots ,x_{n} \right)^{\rm{T}} \end{align}$
到输出的映射,即学习函数$h_{W,b}({x})$满足
(7) $\begin{align} h\left( {x};\theta \right)=h_{W,b}\left( {x} \right)=f\left( {W}^{\rm{T}}{x } + b \right) \end{align}$
其中$\theta $为参数,代表${W},b$。
(8) $\begin{align} {W}=\left( W_{1},W_{2},\cdots ,W_{n} \right)^{\rm{T}} \end{align}$
为对应每个$x_{i}$的权重,$b$为常数项。$f$称为激活函数,在得到输入加权的结果后,用激活函数将该值映射到最终的输出。常见的激活函数有:线性函数(相当于不使用激活函数),ReLU,sigmoid(用于二分类问题),softmax(用于多分类问题),Leaky ReLU,tanh等。
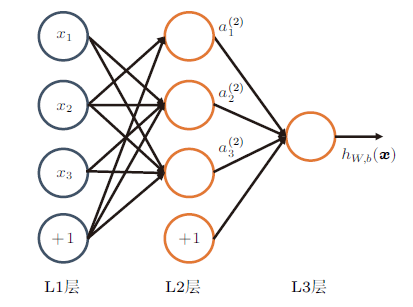
图2
训练神经网络一般使用反向传播算法,本质是一种梯度下降算法,即通过求损失函数$J$关于每个参数的偏导数,然后用梯度下降更新参数。损失函数$J$可以定义成均方误差
(9) $\begin{align} J( \theta )=\frac{1}{N}\sum\limits_{i=1}^N ( h\left( X;\theta \right)-\hat{h}\left( X;\theta \right))^{2} \end{align}$
(10) $\begin{align} \theta^{\left( t+1 \right)}=\theta^{\left( t \right)}-\alpha \nabla _{\theta }J \end{align}$
$\alpha $是学习率,一般设置为一个较小的正数。其中$h(X;\theta)$表示当前参数下神经网络的输出,$\hat{h}(X;\theta)$表示训练的目标值。
对多层的前馈神经网络,使用链式法则求损失函数$J$关于各个参数的梯度。记$W_{ij}^{k}$是第$k-1$层第$j$个神经元连接到第$k$层的第$i$个神经元的权值,$b_{j}^{k}$表示第$k$层第$j$个神经元的偏置,$z_{j}^{k}$表示第$k$层第$j$个神经元的输入,$a_{j}^{k}$表示第$k$层第$j$个神经元的输出,即$a_{j}^{k}= f(z_{j}^{k})$,$f$为激活函数。
第$k$层第$j$个神经元的误差(实际值与预测值的误差)定义为
(11) $\begin{align} \delta_{j}^{k}=\frac{\partial J}{\partial z_{j}^{k}} \end{align}$
(12) $\begin{align} \delta_{j}^{k}=\sum_i \frac{\partial J}{\partial z_{i}^{k+1}} \frac{\partial z_{i}^{k+1}}{\partial z_{j}^{k}}=\sum_i \frac{\partial z_{i}^{k+1}}{\partial z_{j}^{k}} \delta_{i}^{k+1} \end{align}$
(13) $\begin{align} z_{i}^{k+1}\!={}&\sum_j W_{ij}^{k+1} a_{j}^{k}\!+\! b_{j}^{k+1} = \notag\\ {}& \sum_j W_{ij}^{k+1} f\left( z_{j}^{k} \right)\!+\!b_{j}^{k+1} \end{align}$
(14) $\begin{align} \frac{\partial z_{i}^{k+1}}{\partial z_{j}^{k}}=W_{ij}^{k+1}f{'}\left( z_{j}^{k} \right) \end{align}$
代入$\delta_{j}^{k}$的表达式,即得
(15) $\begin{align} \delta_{j}^{k}=\sum_i W_{ij}^{k+1}\delta_{i}^{k+1}f{'}( z_{j}^{k}) \end{align}$
整体梯度下降以及随机梯度下降的收敛速度通常较慢,可使用Adam算法[4 ] 进行优化。
3 数值算例
对于给定初始条件$u=f_{i}(x)$,设$f_{i}(x)$支集为闭区间$E=[-{L}/{2}, {L}/{2}]$。在区间$E_{0}=[-{L_{\rm c}}/{2}, {L_{\rm c}}/{2}]$ 上用二阶Verlet算法对时间离散进行计算,将总长度取得充分长($L_{\rm c}>5L$)并计算足够步数(使波前不超出边界),选取计算区间中一个点作为左边界点,记录对应的$u_{0},\cdots,u_{N-1}\dot{u}_{0},\cdots,\dot{u}_{N-1}$,即得参考数值解,用于训练一个单层的前馈神经网络。该神经网络以$\dot{u}_{0}$为输出,以$u_{0},\cdots,u_{N-1}\dot{u}_{1},\cdots,\dot{u}_{N-1}$为输入。由线性约束假设(4),函数应该是线性的,因此选取激活函数为线性激活函数,即$f(x)=x$。因为区间上原子位移全部为零对应于原子链静止的情形,边界原子的速度也一定是零,因此零输入一定对应零输出,所以偏置$b$取为零。于是训练得到的神经元的权值就是边界条件(4)中的系数。
以$N=6$为例,取$L=120$, $L_{\rm c}=1200$,令$j_{lb}=-90$处作为左边界点。取初值为
(16) $\begin{align} u_{j}=\begin{cases} \dfrac{A}{2M-1} \left(\sum_{k=1}^M \cos \dfrac{j}{L} \dfrac{\pi }{k} + \sum_{k=1}^{\left\lceil {M}/{2} \right\rceil} \cos \dfrac{j}{L}\left( 2k-1 \right)\pi +\sum\limits_{k=1}^{\left\lfloor {M}/{2} \right\rfloor} \sin \dfrac{j}{L}2k\pi \right), & j\in \left[ -\dfrac{L}{2},\dfrac{L}{2} \right] \\ 0, & j\notin \left[ -{L}/{2},{L}/{2} \right] \end{cases} \end{align}$
$A$为任意正常数,$M$为正整数,这里令$A=50$,$M=17$。离散时间步长$\Delta t=0.005$,则单位时间有200步,计算400个单位时间。将$u_{j}^{n}$, $j=j_{lb}+1,j_{lb}+2,\cdots ,j_{lb}+6$及$\dot{u}_{j}^{n}$, $j=j_{lb}+0,j_{lb}+1,\cdots,j_{lb}+6$作为训练集的输入,$u_{j_{lb}}^{n}$作为训练集的输出。训练200轮之后得到系数$c_{j}b_{j}$, $j=0,1,2,\cdots,6$(如表1 所示)。 与文献[3 ] 提出的边界条件(表2 所示)对比,两者差别很大。为了验证这组系数的正确性,在区间[-50,50]上取初值
(17) $\begin{align} u_{n} \!=\! h_{0} \big(e^{-(\frac{n}{20})^{2}}-{e}^{-\frac{25}{4}} \big) \Big[1\!+\! \frac{1}{10}\cos \Big(\frac{2}{5} n \pi \Big)\Big] \end{align}$
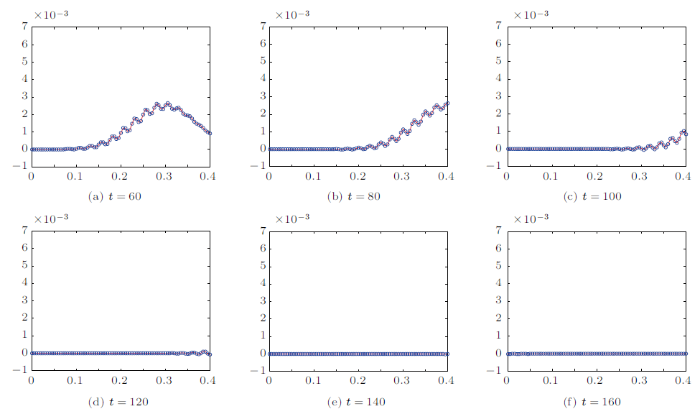
其中$h_{0}=\dfrac{50}{1-{e}^{-6.25}}$,离散时间步长$\Delta t=0.005$,计算符合人工边界条件的数值解并在[-500,500]上计算参考数值解,结果如图3 所示。
图3
图3
$N= 6$时机器学习方法与参考解的数值结果比较,实线代表参考解,圆圈代表采用人工边界条件的数值解。由于解的对称性,只画出了通过右侧边界的波形
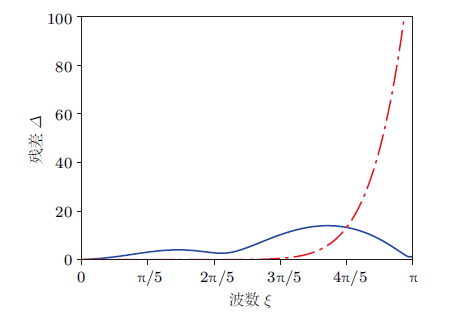
然后分析机器学习方法得到的边界条件的残差。计算$\varDelta $关于$\xi$的关系,结果如图4 所示。
图4
图4
$N=6$时$\varDelta $关于$\xi$的关系,其中点线与$\xi$ 轴重合,表示精确的边界条件,点划线代表文献[3 ] 提出的人工边界条件的残差,实线代表机器学习得到的人工边界条件的残差
从图4 中可见,文献[3 ] 提出的人工边界条件的残差在$\xi\to \pi $,即短波处发散到无穷。而机器学习得到的人工边界条件虽然在$\xi \to 0$,即长波处残差较大,但是短波处残差是有界的。
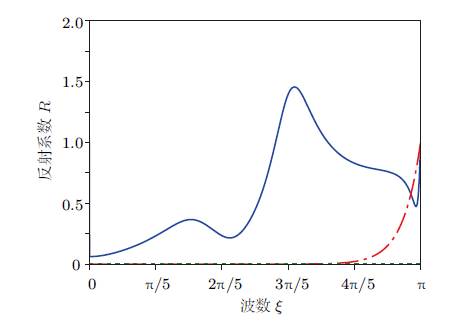
为进一步考察机器学习得到的人工边界条件在能量意义下的精确度,计算边界条件对应的反射系数$R$关于$\xi$的关系,结果如图5 所示。这里有反射系数大于1的波段,但前述算例仍是稳定的;此外,还可以通过在训练数据中增加更多这个波段的模态来改善。
图5
图5
$N=6$时$R$关于$\xi $的关系,其中点线与$\xi$轴重合,表示精确的边界条件,点划线代表文献[3 ] 出的人工边界条件的反射系数,实线代表机器学习得到的人工边界条件的反射系数
4 结论
对于线性原子链的人工边界条件这一问题,本文在基于泰勒展开的匹配边界条件方法基础上,提出了基于前馈神经网络的机器学习算法。该方法不需要任何对方程(1)的细致分析就能得到一组较好的边界条件。虽然该方法在一维线性原子链模型上的应用仍然存在残差和反射系数较大的问题,但是应用该方法需要的先验知识很少,编程方便且容易实现,因此具有较高的实用价值,可以进一步推广到其他人工边界条件的设计。
参考文献
View Option
[1]
唐少强 , 王贤明 . 波传播计算中的人工边界条件
力学与实践 , 2010 ,32 (2 ):1 -8
[本文引用: 1]
Tang Shaoqiang Wang Xianming . Artificial boundary conditions for wave propagation simulation
Mechanics in Engineering , 2010 ,32 (2 ):1 -8 (in Chinese)
[本文引用: 1]
[2]
Cai W de Koning M Bulatov VV , et al . Minimizing boundary reflections in coupled-domain simulations
Physical Review Letters , 2000 ,85 (15 ):3213
[本文引用: 1]
[3]
Wang X Tang S . Matching boundary conditions for lattice dynamics
International Journal for Numerical Methods in Engineering , 2013 ,93 (12 ):1255 -1285
[本文引用: 6]
[4]
Kingma D Ba JA . A method for stochastic optimization.
International Conference on Learning Representations, Banff,Canada , 2014
[本文引用: 1]
波传播计算中的人工边界条件
1
2010
... 分子动力学计算常用于精细分析材料的性质,往往采用周期边界条件.对于多尺度计算和其他一些力学研究,周期边界条件不适用,需要设计人工边界条件[1 ] .本文将针对一维线性原子链,运用机器学习设计人工边界条件.该方法需要的先验知识很少,且可以快速产生一系列边界条件. ...
波传播计算中的人工边界条件
1
2010
... 分子动力学计算常用于精细分析材料的性质,往往采用周期边界条件.对于多尺度计算和其他一些力学研究,周期边界条件不适用,需要设计人工边界条件[1 ] .本文将针对一维线性原子链,运用机器学习设计人工边界条件.该方法需要的先验知识很少,且可以快速产生一系列边界条件. ...
Minimizing boundary reflections in coupled-domain simulations
1
2000
... 传统的获得人工边界条件的方法有时间历史积分[2 ] 与在给定波数附近进行泰勒展开的方法[3 ] 等.本文提出的方法主要是受后者的启发. ...
Matching boundary conditions for lattice dynamics
6
2013
... 传统的获得人工边界条件的方法有时间历史积分[2 ] 与在给定波数附近进行泰勒展开的方法[3 ] 等.本文提出的方法主要是受后者的启发. ...
... $A$为任意正常数,$M$为正整数,这里令$A=50$,$M=17$.离散时间步长$\Delta t=0.005$,则单位时间有200步,计算400个单位时间.将$u_{j}^{n}$, $j=j_{lb}+1,j_{lb}+2,\cdots ,j_{lb}+6$及$\dot{u}_{j}^{n}$, $j=j_{lb}+0,j_{lb}+1,\cdots,j_{lb}+6$作为训练集的输入,$u_{j_{lb}}^{n}$作为训练集的输出.训练200轮之后得到系数$c_{j}b_{j}$, $j=0,1,2,\cdots,6$(如表1 所示). 与文献[3 ] 提出的边界条件(表2 所示)对比,两者差别很大.为了验证这组系数的正确性,在区间[-50,50]上取初值 ...
... $N=6$时文献[3 ] 提出的人工边界条件的系数 ...
... 然后分析机器学习方法得到的边界条件的残差.计算$\varDelta $关于$\xi$的关系,结果如
图4 所示.
10.6052/1000-0879-19-412.F004 图4 $N=6$时$\varDelta $关于$\xi$的关系,其中点线与$\xi$ 轴重合,表示精确的边界条件,点划线代表文献<sup>[<xref ref-type="bibr" rid="b3">3</xref>]</sup>提出的人工边界条件的残差,实线代表机器学习得到的人工边界条件的残差 ![]()
从图4 中可见,文献[3 ] 提出的人工边界条件的残差在$\xi\to \pi $,即短波处发散到无穷.而机器学习得到的人工边界条件虽然在$\xi \to 0$,即长波处残差较大,但是短波处残差是有界的. ...
... 从图4 中可见,文献[3 ] 提出的人工边界条件的残差在$\xi\to \pi $,即短波处发散到无穷.而机器学习得到的人工边界条件虽然在$\xi \to 0$,即长波处残差较大,但是短波处残差是有界的. ...
... 为进一步考察机器学习得到的人工边界条件在能量意义下的精确度,计算边界条件对应的反射系数$R$关于$\xi$的关系,结果如
图5 所示.这里有反射系数大于1的波段,但前述算例仍是稳定的;此外,还可以通过在训练数据中增加更多这个波段的模态来改善.
10.6052/1000-0879-19-412.F005 图5 $N=6$时$R$关于$\xi $的关系,其中点线与$\xi$轴重合,表示精确的边界条件,点划线代表文献<sup>[<xref ref-type="bibr" rid="b3">3</xref>]</sup>出的人工边界条件的反射系数,实线代表机器学习得到的人工边界条件的反射系数 ![]()
4 结论 对于线性原子链的人工边界条件这一问题,本文在基于泰勒展开的匹配边界条件方法基础上,提出了基于前馈神经网络的机器学习算法.该方法不需要任何对方程(1)的细致分析就能得到一组较好的边界条件.虽然该方法在一维线性原子链模型上的应用仍然存在残差和反射系数较大的问题,但是应用该方法需要的先验知识很少,编程方便且容易实现,因此具有较高的实用价值,可以进一步推广到其他人工边界条件的设计. ...
A method for stochastic optimization.
1
2014
... 整体梯度下降以及随机梯度下降的收敛速度通常较慢,可使用Adam算法[4 ] 进行优化. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}